




Originally posted at Serverless
As your Serverless app starts to grow, you reach a point where you are trying to figure out how best to organize it. In this post we’ll share some of the best practices for organizing and managing large Serverless applications.
Here are a few things we’ll be covering:
Organizing your services in repos
Organizing Lambda functions
Sharing dependencies
Sharing code between services
Sharing serverless.yml config
Sharing an API Gateway endpoint
Deploying an entire app
A quick reminder on the definitions before we get started. An app is a collection of services. Where a service is configured using a single serverless.yml file.
Organizing services
There are some very passionate arguments on the advantages and disadvantages of a monorepo vs multi-repo setup. We are not going to be focusing on their specific details here. But we want to pick a setup that allows us to:
Share code and config easily between services
Make it easy to create and configure new environments from the repos
And make our deployment process as simple as possible
For starters, Serverless effectively requires you to adopt the infrastructure as code paradigm. This usually makes it so that your AWS resources and business logic code end up being closely coupled. But often you can draw a line between the resources that get updated frequently and the ones that aren’t. For example, your Lambda functions and API Gateway endpoints get updated fairly frequently. While, resources like DynamoDB, Cognito, or S3 are less likely to do so.
Additionally, your Lambda functions have all your business logic code. They need to be able to share code and config easily between themselves.
So if you are creating a Serverless API backend, you’ll have roughly two types of resources: your infrastructure resources and the Lambda functions for your API endpoints. It often ends up easier to keep them in separate repos.
Why? Most of the code changes are going to happen in the repo with the Lambda functions. When your team is making rapid changes, you are likely to have many feature branches, bug fixes, and pull requests. A bonus with Serverless is that you can spin up new environments at zero cost (you only pay for usage, not for provisioning resources). So, a team can have dozens of ephemeral stages such as: prod, staging, dev, feature-x, feature-y, feature-z, bugfix-x, bugfix-y, pr-128, pr-132, etc. This ensures each change is tested on real infrastructure before being promoted to production.
On the other hand, changes are going to happen less frequently to the infrastructure repo. And most likely you don’t need a complete set of standalone DynamoDB tables for each feature branch. In fact, a team will usually have a couple of long-lived environments: dev and prod (and optionally staging). While the feature/bugfix/PR environments of the Lambda functions will connect to the dev environment of the resources.
Here’s a little diagram to illustrate the above setup.
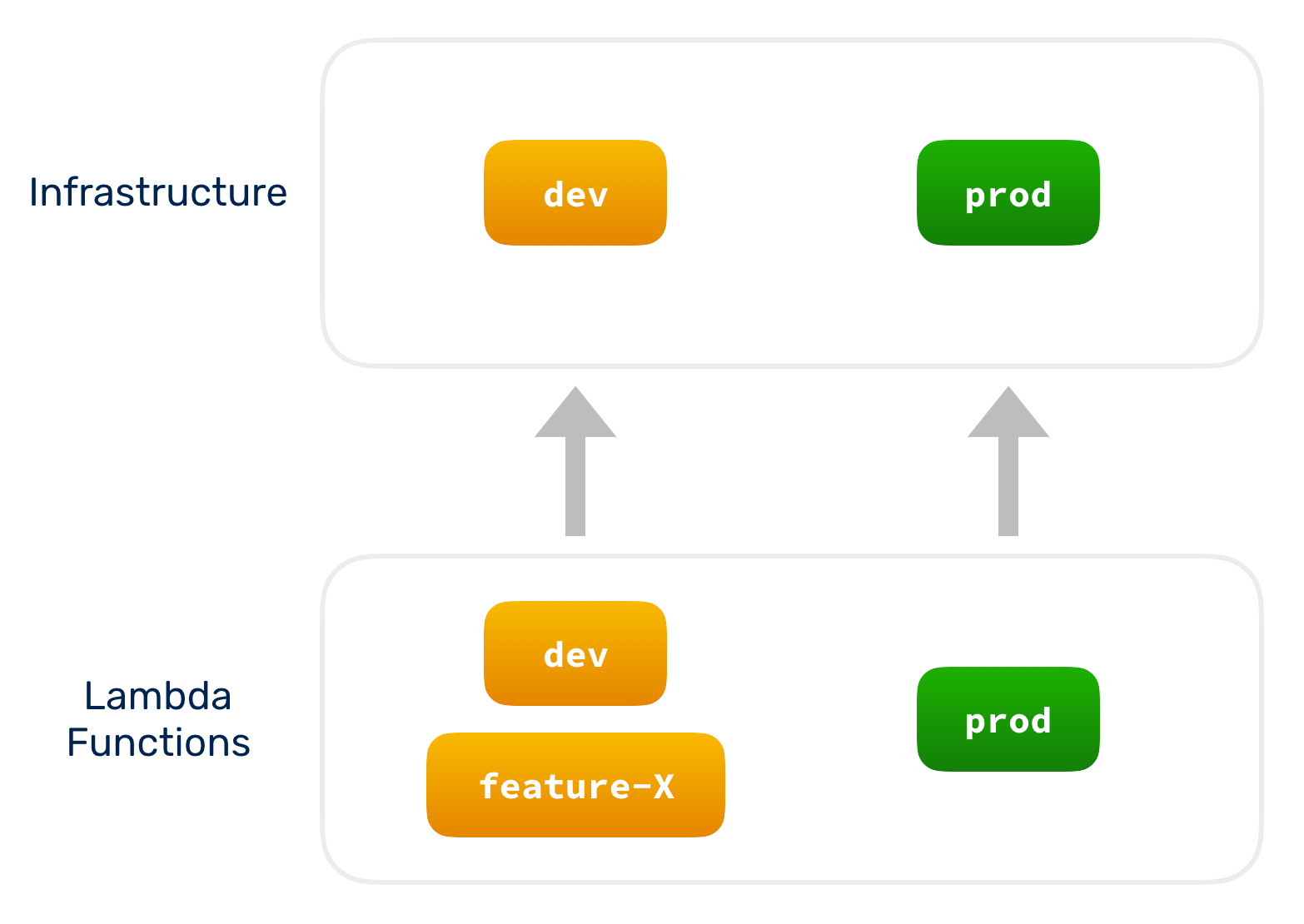
Organizing your Lambda functions
Now that we have our repos organized, let’s take a look at how we structure the code for our Lambda functions.
Sharing dependencies
Let’s start by looking at how you’ll set up your dependencies. We’ll be looking at a Node.js example here. Continuing from the above example, let’s have a look at how the repo for your Lambda functions:
The first question you’ll typically have is about the package.jon is — "Do I just have one package.json or do I have one for each service?". We recommend having multiple package.json files. You could use something like Lerna or Yarn Workspaces here but we are keeping things simple. We want you to be able to use this setup as a starting point for your projects and leave that option up to you.
We use the package.json at the project root to install the dependencies that will be shared across all the services. For example, if you are using serverless-bundle to optimally package the Lambda functions, or using the serverless-plugin-warmup to reduce cold starts, they should be installed at the root level. It doesn’t make sense to install them in each and every single service.
On the other hand, dependencies that are specific to a single service are installed in the package.json for that service. In our example, the billing-api service uses the stripe NPM package. So it’s added just to that package.json.
This setup implies that when you are deploying your app through a CI; you’ll need to do an npm install twice. Once at the root and once in a specific service directory.
Sharing code between services
The biggest reason to use a monorepo setup is to be able to easily share common code between your services.
Alternatively, you could use a multi-repo approach where all your common code is published as private NPM packages. This adds an extra layer of complexity. This only makes sense if you grow to the point where different teams are working on different services while sharing the same common code. In this scenario, making updates to the common code can potentially affect a very large number of services and Lambda functions. For this case it just makes a lot more sense to host your common code in versioned packages. This allows teams to explicitly decide when they want to update the common code.
In our example, we’ll try to share some common code. We’ll be placing these in a libs/ directory. Our services need to make calls to various AWS services using the AWS SDK. And we have the common SDK configuration code in the libs/aws-sdk.js file. For example, we might want to optionally enable tracing through AWS X-Ray across all of our services.
Our Lambda functions will now import this, instead of the standard AWS SDK.
The great thing about this is that we can easily change any AWS related config and it’ll apply across all of our services.
Sharing serverless.yml config
We have separate serverless.yml configs for our services. However, we might need to share some config across all of our serverless.yml files. To do that:
Place the shared config values in a common yaml file at the root.
And reference them in your individual serverless.yml files.
For example, we want to be able to use X-Ray, we need to grant the necessary X-Ray permissions in the Lambda IAM role. So we added a serverless.common.yml at the repo root.
And in each of our services, we include the lambdaPolicyXRay IAM policy:
Sharing an API Gateway endpoint
A challenge that you run into when splitting your APIs into multiple services is sharing the same domain for them. You might recall that APIs that are created as a part of a service get their own unique URL that looks something like:
When you attach a custom domain for your API, it’s attached to a specific endpoint like the one above. This means that if you create multiple API services, they will all have unique endpoints.
You can assign different base paths for your custom domains. For example, api.example.com/notes can point to one service while api.example.com/billing can point to another. But if you try to split your notes service up, you’ll face the challenge of sharing a custom domain across them.
In our example app, we have two services with API endpoints, notes-api and billing-api. Let's look at how to configure API Gateway such that both services are served out via a single API endpoint.
In the notes-api, we will export the API Gateway resources:
And in the billing-api, we will import the above:
This allows us to share the same endpoint across these two services. Next let’s look at how to deploy our app.
Deploying the entire app
Our services have a couple of interdependencies. This adds a bit of a wrinkle to our deployment process. Let’s look at this in detail.
First deployment
Note that by sharing an API Gateway project, we are making the billing-api depend on the notes-api. When deploying for the first time, you need to ensure the notes-api is deployed first.
If both the services are deployed concurrently, the billing-api will fail simply because the ARN referenced in its serverless.yml does not exist. This makes sense because we haven’t created it yet!
Subsequent deployments
Once all the services have been successfully deployed, you can deploy them all concurrently. This is because the referenced ARN has already been created.
Adding new dependencies
Say you add a new SNS topic in the notes-api service and you want the billing-api service to subscribe to that topic. The first deployment after the change, will again fail if all the services are deployed concurrently. You need to deploy the notes-api service before deploying the billing-api service.
Deploying only updated services
Once your application grows and you have dozens of services, you’ll notice that repeatedly deploying all your services is not very fast. One way to speed it up is to only deploy the services that’ve been updated. You can do this by checking if there are any commits in a service’s directory.
Upon deployment, you can run the following command to get a list of updates:
This will give you a list of files that have been updated between the two commits. With the list of changed files, there are three scenarios from the perspective of a given service. We are going to use notes-api as an example:
A file was changed in my service’s directory (ie. services/notes-api) ⇒ we deploy the notes-api service.
A file was changed in another service’s directory (ie. services/billing-api) ⇒ we do not deploy the notes-api service.
Or, a file was changed in libs/ ⇒ we deploy the notes-api service.
Your repo setup can look different, but the general concept still holds true. You have to figure out if a file change affects an individual service, or if a file change affects all the services. The advantage of this strategy is that you know upfront which services can be skipped. This allows you to skip a portion of the entire build process, thus speeding up your builds. A shameless plug here, Seed supports this and the setup outlined in this post out of the box!
Summary
Hopefully, this post gives you a good idea of how to structure your Serverless application. We’ve seen the above setup work really well for folks in production. It gives you enough structure to help you as your app and team grows. While still allowing you to retain the flexibility to make changes along the way.
Give this setup a try and make sure to share your feedback in the comments below!