




Originally posted at Serverless on July 2nd, 2019

Exposing a simple database via a GraphQL API requires a lot of custom code and infrastructure: true or false?
For those who answered “true,” we’re here to show you that building GraphQL APIs is actually fairly easy, with some concrete examples to illustrate why and how.
(If you already know how easy it is to build GraphQL APIs with Serverless, there’s plenty for you in this article as well.)
GraphQL is a query language for web APIs. There’s a key difference between a conventional REST API and APIs based on GraphQL: with GraphQL, you can use a single request to fetch multiple entities at once. This results in faster page loads and enables a simpler structure for your frontend apps, resulting in a better web experience for everyone. If you’ve never used GraphQL before, we suggest you check out this GraphQL tutorial for a quick intro.
The Serverless framework is a great fit for GraphQL APIs: with Serverless, you don’t need to worry about running, managing, and scaling your own API servers in the cloud, and you won’t need to write any infrastructure automation scripts. Learn more about Serverless here. In addition, Serverless provides an excellent vendor-agnostic developer experience and a robust community to help you in building your GraphQL applications.
Many applications in our everyday experience contain social networking features, and that kind of functionality can really benefit from implementing GraphQL instead of the REST model, where it’s hard to expose structures with nested entities, like users and their Twitter posts. With GraphQL, you can build a unified API endpoint that allows you to query, write, and edit all the entities you need using a single API request.
In this article, we look at how to build a simple GraphQL API with the help of the Serverless framework, Node.js, and any of several hosted database solutions available through Amazon RDS: MySQL, PostgreSQL, and the MySQL workalike Amazon Aurora.
Follow along in this example repository on GitHub, and let’s dive in!
Building a GraphQL API with a relational DB backend
In our example project, we decided to use all three databases (MySQL, PostgreSQL, and Aurora) in the same codebase. We know, that’s overkill even for a production app, but we wanted to blow you away with how web-scale we build. 😉
But seriously, we overstuffed the project just to make sure you’d find a relevant example that applies to your favorite database. If you’d like to see examples with other databases, please let us know in the comments.
Defining the GraphQL schema
Let’s start by defining the schema of the GraphQL API that we want to create, which we do in the schema.gql file at the root of our project using the GraphQL syntax. If you're unfamiliar with this syntax, take a look at the examples on this GraphQL documentation page.
For starters, we add the first two items to the schema: a User entity and a Post entity, defining them as follows so that each User can have multiple Post entities associated with it:
type User {
UUID: String
Name: String
Posts: [Post]
}
type Post {
UUID: String
Text: String
}
We can now see what the User and Post entities look like. Later, we’ll make sure these fields can be stored directly in our databases.
Next, let’s define how users of the API will query these entities. While we could use the two GraphQL types User and Post directly in our GraphQL queries, it's best practice to create input types instead to keep the schema simple. So we go ahead and add two of these input types, one for the posts and one for the users:
input UserInput {
Name: String
Posts: [PostInput]
}
input PostInput {
Text: String
}
Now let’s define the mutations-the operations that modify the data stored in our databases via our GraphQL API. For this we create a Mutation type. The only mutation we'll use for now is createUser. Since we're using three different databases, we add a mutation for each database type. Each of the mutations accepts the input UserInput and returns a User entity:
We also want to provide a way to query the users, so we create a Query type with one query per database type. Each query accepts a String that's the user's UUID, returning the User entity that contains its name, UUID, and a collection of every associated Pos``t:
Finally, we define the schema and point to the Query and Mutation types:
schema { query: Query mutation: Mutation }
We now have a full description for our new GraphQL API! You can see the whole file here.
Defining handlers for the GraphQL API
Now that we have a description of our GraphQL API, we can write the code we need for each query and mutation. We start by creating a handler.js file in the root of the project, right next to the schema.gql file we created previously.
handler.js's first job is to read the schema:
The typeDefs constant now holds the definitions for our GraphQL entities. Next, we specify where the code for our functions is going to live. To keep things clear, we'll create a separate file for each query and mutation:
The resolvers constant now holds the definitions for all our API's functions. Our next step is to create the GraphQL server. Remember the graphql-yoga library we required above? We'll use that library here to create a working GraphQL server easily and quickly:
Finally, we export the GraphQL handler along with the GraphQL Playground handler (which will allow us to try out our GraphQL API in a web browser):
Okay, we’re done with the handler.js file for now. Next up: writing code for all functions that access the databases.
Writing code for the queries and the mutations
We now need code to access the databases and to power our GraphQL API. In the root of our project, we create the following structure for our MySQL resolver functions, with the other databases to follow:
Common queries
In the Common folder, we populate the mysql.js file with what we'll need for the createUser mutation and the getUser query: an init query, to create tables for Users and Posts if they don't exist yet; and a user query, to return a user's data when creating and querying for a user. We'll use this in both the mutation and the query.
The init query creates both the Users and the Posts tables as follows:
The getUser query returns the user and their posts:
Both of these functions are exported; we can then access them in the handler.js file.
Writing the mutation
Time to write the code for the createUser mutation, which needs to accept the name of the new user, as well as a list of all posts that belong to them. To do this we create the resolver/Mutation/mysql_createUser.js file with a single exported func function for the mutation:
The mutation function needs to do the following things, in order:
Connect to the database using the credentials in the application’s environment variables.
Insert the user into the database using the username, provided as input to the mutation.
Also insert any posts associated with the user, provided as input to the mutation.
Return the created user data.
Here’s how we accomplish that in code:
You can see the full file that defines the mutation here.
Writing the query
The getUser query has a structure similar to the mutation we just wrote, but this one's even simpler. Now that the getUser function is in the Common namespace, we no longer need any custom SQL in the query. So, we create the resolver/Query/mysql_getUser.js file as follows:
You can see the full query in this file.
Bringing everything together in the serverless.yml file
Let’s take a step back. We currently have the following:
A GraphQL API schema.
A handler.js file.
A file for common database queries.
A file for each mutation and query.
The last step is to connect all this together via the serverless.yml file. We create an empty serverless.yml at the root of the project and start by defining the provider, the region and the runtime. We also apply the LambdaRole IAM role (which we define later here) to our project:
We then define the environment variables for the database credentials:
Notice that all the variables reference the custom section, which comes next and holds the actual values for the variables. Note that password is a terrible password for your database and should be changed to something more secure (perhaps p@ssw0rd 😃):
What are those references after Fn::GettAtt, you ask? Those refer to database resources:
The resource/MySqlRDSInstance.yml file defines all the attributes of the MySQL instance. You can find its full content here.
Finally, in the serverless.yml file we define two functions, graphql and playground. The graphql function is going to handle all the API requests, and the playground endpoint will create an instance of GraphQL Playground for us, which is a great way to try out our GraphQL API in a web browser:
Now MySQL support for our application is complete!
You can find the full contents of the serverless.yml file here.
Adding Aurora and PostgreSQL support
We’ve already created all the structure we need to support other databases in this project. To add support for Aurora and Postgres, we need only define the code for their mutations and queries, which we do as follows:
Add a Common queries file for Aurora and for Postgres.
Add configuration in the serverless.yml file for all the environment variables and resources needed for both databases.
At this point, we have everything we need to deploy our GraphQL API, powered by MySQL, Aurora, and PostgreSQL.
Deploying and testing the GraphQL API
Deployment of our GraphQL API is simple.
First we run npm install to put our dependencies in place.
Then we run npm run deploy, which sets up all our environment variables and performs the deployment.
Under the hood, this command runs serverless deploy using the right environment.
That’s it! In the output of the deploy step we'll see the URL endpoint for our deployed application. We can issue POST requests to our GraphQL API using this URL, and our Playground (which we'll play with in a second) is available using GET against the same URL.
Trying out the API in the GraphQL Playground
The GraphQL Playground, which is what you see when visiting that URL in the browser, is a great way to try out our API.
Let’s create a user by running the following mutation:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
In this mutation, we call the mysql_createUser API, supply the text of the new user's posts, and indicate that we want to get the user's name and the UUID back as the response.
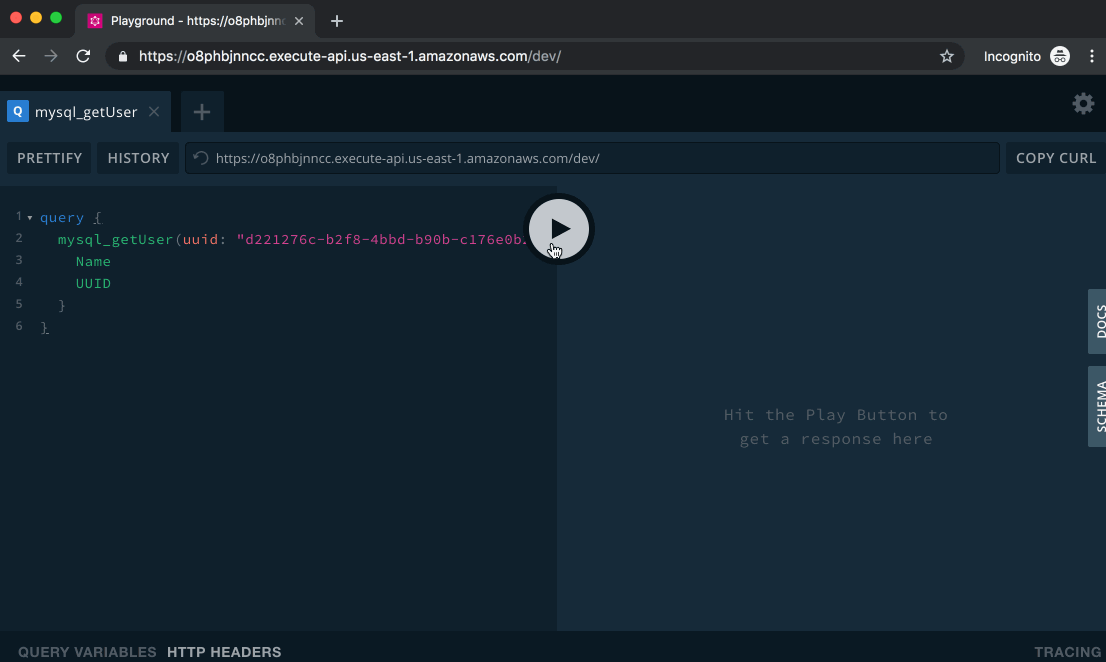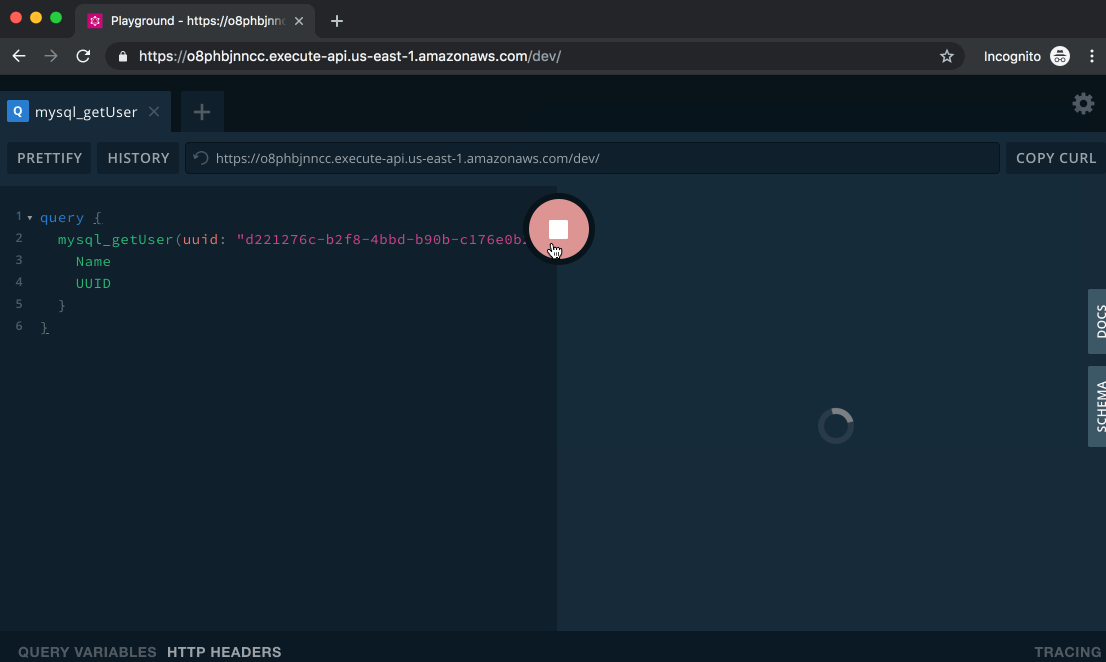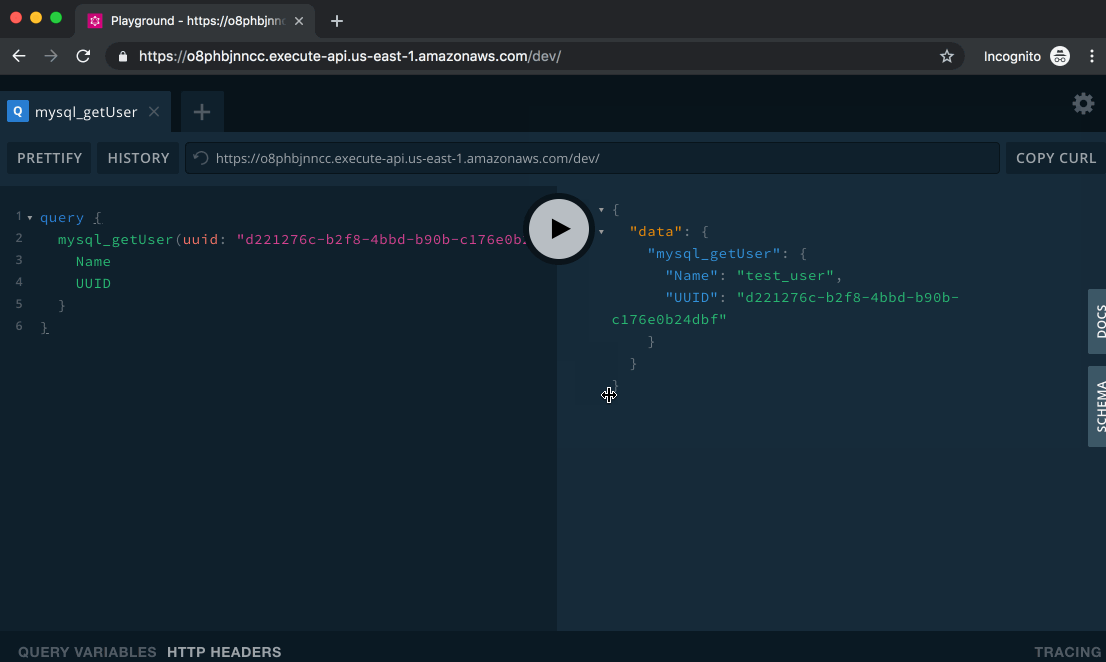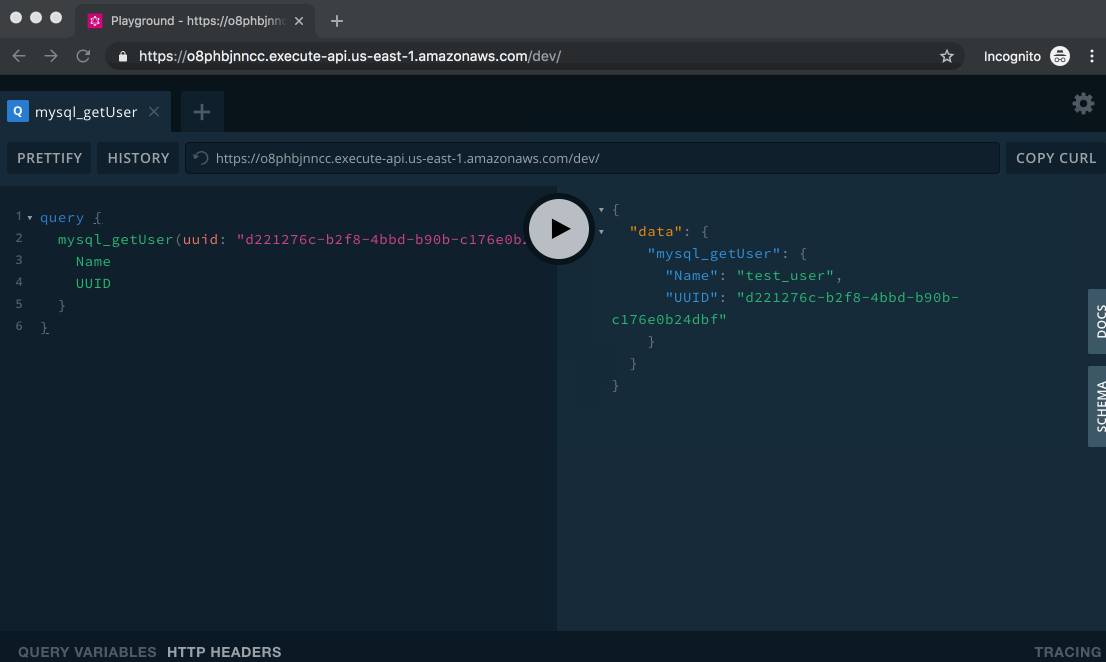
Paste the above text into the left side of the Playground and click the Play button. On the right, you’ll see the output of the query:
Now let’s query for this user:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
This gives us back the name and the UUID of the user we just created. Neat!
We can do the same with the other backends, PostgreSQL and Aurora. For that, we just need to replace the names of the mutation with postgres_createUser or aurora_createUser, and queries with postgres_getUser or aurora_getUser. Try it out yourself! (Keep in mind that the users are not synced between the databases, so you'll only be able to query for users that you've created in each specific database.)
Comparing the MySQL, PostgreSQL, and Aurora implementations
To begin with, mutations and queries look exactly the same on Aurora and MySQL, since Aurora is MySQL-compatible. And there are only minimal code differences between those two and the Postgres implementation.
In fact, for simple use cases, the biggest difference between our three databases is that Aurora is available only as a cluster. The smallest available Aurora configuration still includes one read-only and one write replica, so we need a clustered configuration even for this basic Aurora deployment.
Aurora offers faster performance than MySQL and PostgreSQL, due mainly to the SSD optimizations Amazon made to the database engine. As your project grows, you’ll likely find that Aurora offers improved database scalability, easier maintenance, and better reliability compared to the default MySQL and PostgreSQL configurations. But you can make some of these improvements on MySQL and PostgreSQL as well if you tune your databases and add replication.
For test projects and playgrounds we recommend MySQL or PostgreSQL. These can run on db.t2.micro RDS instances, which are part of the AWS free tier. Aurora doesn't currently offer db.t2.micro instances, so you'll pay a bit more to use Aurora for this test project.
A final important note
Remember to remove your Serverless deployment once you’ve finished trying out the GraphQL API so that you don’t keep paying for database resources you’re no longer using.
You can remove the stack created in this example by running npm run remove in the root of the project.
Happy experimenting!
Summary
In this article we walked you through creating a simple GraphQL API, using three different databases at once; though this isn’t something you’d ever do in reality, it allowed us to compare simple implementations of the Aurora, MySQL, and PostgreSQL databases. We saw that the implementation for all three databases is roughly the same in our simple case, barring minor differences in the syntax and the deployment configurations.
You can find the full example project that we’ve been using in this GitHub repo. The easiest way to experiment with the project is to clone the repo and deploy it from your machine using npm run deploy.
For more GraphQL API examples using Serverless, check out the serverless-graphql repo.
If you’d like to learn more about running Serverless GraphQL APIs at scale, you might enjoy our article series “Running a scalable & reliable GraphQL endpoint with Serverless”
Maybe GraphQL just isn’t your jam, and you’d rather deploy a REST API? We’ve got you covered: check out this blog post for some examples.
Questions? Comment on this post, or create a discussion in our forum.
Originally published at https://www.serverless.com.