


Using TensorFlow and the Serverless Framework for deep learning and image recognition


Originally posted at Serverless on July 24th, 2018
Deep and machine learning is becoming essential for a lot of businesses, be it for internal projects or external ones.
The data-driven approach allows companies to build analytics tools based on their data, without constructing complicated deterministic algorithms. Deep learning allows them to use more raw data than a machine learning approach, making it applicable to a larger number of use cases. Also, by using pre-trained neural networks, companies can start using state of the art applications like image captioning, segmentation and text analysis-without significant investment into data science team.
But one of the main issues companies face with deep/machine learning is finding the right way to deploy these models.
I wholeheartedly recommend a serverless approach. Why? Because serverless provides a cheap, scalable and reliable architecture for deep learning models.
In this post, we’ll cover how to build your first deep learning API using the Serverless Framework, TensorFlow, AWS Lambda and API Gateway.
We will cover the following:
Using serverless for deep learning — standard ways of deploying deep learning applications, and how a serverless approach can be beneficial.
“Hello world” code — a basic Lambda function with only 4 lines of code. There is no API here, we’ll start with the simplest possible example.
Code decomposition — looking through the configuration file, and the python code for handling the model, to understand how the whole example works.
API example — get a working API for image recognition on top of our example.
If you want to skip the background about what TensorFlow is and why you’d want to use serverless for machine learning, the actual example starts here.
Why Serverless + TensorFlow?
First of all, let’s briefly cover what TensorFlow is: an open source library that allows developers to easily create, train and deploy neural networks. It’s currently the most popular framework for deep learning, and is adored by both novices and experts.
Currently, the way to deploy pre-trained TensorFlow model is to use a cluster of instances.
So to make deep learning API, we would need stack like this:
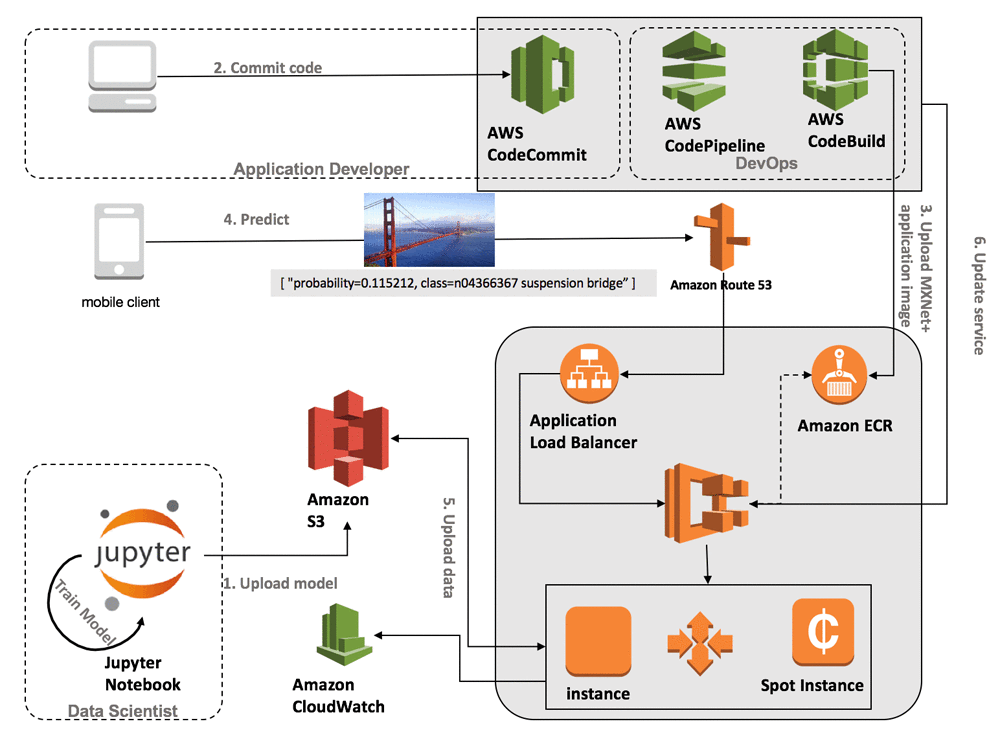
The main pain points in this infrastructure is that:
you have to manage the cluster — its size, type and logic for scaling
you have to pay for unused server power
you have to manage the container logic — logging, handling of multiple requests, etc
With AWS Lambda, we can make the stack significantly easier and use simpler architecture:
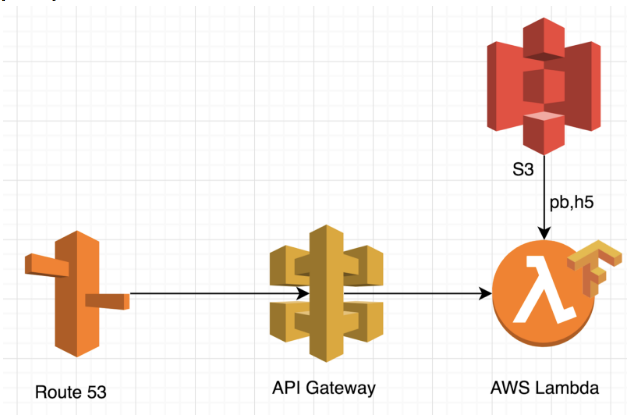
The difference in both approaches
First of all, a serverless serverless approach is very scalable. It can scale up to 10k concurrent requests without writing any additional logic. It’s perfect for handling random high loads, as it doesn’t take any additional time to scale.
Second, you don’t have to pay for unused server time. Serverless architectures have pay-as-you-go model. Meaning, if you have 25k requests per month, you will only pay for 25k requests.
And not only does it make pricing completely transparent, it’s just a lot cheaper. For the example TensorFlow model we’ll cover in this post, it costs 1$ for about 25k requests. A similar cluster would cost a lot more, and you’d only achieve pricing parity once you hit 1M requests.
Third, infrastructure itself becomes a lot easier. You don’t have to handle Docker containers, logic for multiple requests, or cluster orchestration.
Bottom line: you don’t have to hire someone to do devops for this, as any backend developer can easily handle it.
As we’ll see in a minute, deploying a serverless deep/machine learning infrastructure can be done with as little as 4 lines of code.
That said, when wouldn’t you go with a serverless approach? There are some limitations to be aware of:
Lambda has strict limits in terms of processing time and used memory, you’ll want to make sure you won’t be hitting those
As mentioned above, clusters are more cost effective after a certain number of requests. In cases where you don’t have peak loads and the number of requests is really high (I mean 10M per month high), a cluster will actually save you money.
Lambda has a small, but certain, startup time. TensorFlow also has to download the model from S3 to start up. For the example in this post, a cold execution will take 4.5 seconds and a warm execution will take 3 seconds. It may not be critical for some applications, but if you are focused on real-time execution then a cluster will be more responsive.
The basic 4 line example
Let’s get started with our serverless deep learning API!
For this example, I’m using a pretty popular application of neural networks: image recognition. Our application will take an image as input, and return a description of the object in it.
These kinds of applications are commonly used to filter visual content or classify stacks of images in certain groups. Our app will try to recognize this picture of a panda:

Note: The model and example are also available here.
We’ll use the following stack:
API Gateway for managing requests
AWS Lambda for processing
Serverless framework for handling deployment and configuration
“Hello world” code
To get started, you’ll need to have the Serverless Framework installed.
Create an empty folder and run following commands in the CLI:
You’ll receive the following response:
As you can see, our application successfully recognized this picture of a panda (0.89 score).
That’s it. You’ve just successfully deployed to AWS Lambda with TensorFlow, using the Inception-v3 model for image recognition!
Code decomposition — breaking down the model
Let’s start with serverless YAML file. Nothing uncommon here-we’re using a pretty standard deployment method:
If we will look into the index.py file itself, we will see that first we need to download the model (.pb file) to the AWS Lambda .tmp folder, and then load it via a standard TensorFlow import function.
Here are the parts you have to keep in mind if you want to put your own model, with the links straight to the full code in GitHub:
**Getting predictions from the model:**
Now, let’s move on, and add an API to this!
API example
The simplest way to add an API to the example is to modify the serverless YAML file:
Then, we redeploy the stack:
And receive the following response:
To test the link, we can just open it in the browser:
https://.execute-api.us-east-1.amazonaws.com/dev/handler
Or run curl:
We will receive:
Conclusion
We’ve created a TensorFlow endpoint on AWS Lambda via the Serverless Framework. Setting everything up was extremely easy, and saved us a lot of time over the more traditional approach.
By modifying the serverless YAML file, you can connect SQS and, say, create a deep learning pipeline, or even connect it to a chatbot via AWS Lex.
As a hobby, I port a lot of libraries to make the serverless friendly. You can look at them here. They all have an MIT license, so feel free to modify and use them for your project.
The libraries include the following examples:
Machine learning libraries (Scikit, LightGBM)
Computer vision libraries (Skimage, OpenCV, PIL)
OCR libraries (Tesseract)
NLP libraries (Spacy)
Web scraping libraries (Selenium, PhantomJS, lxml)
Load testing libraries (WRK, pyrestest)
I’m excited to see how others are using serverless to empower their development. Feel free to drop me a line in the comments, and happy developing!
Originally published at https://www.serverless.com.